介绍一个Variational Auto-Encoder生成中国五言绝句的算法
模型结构:
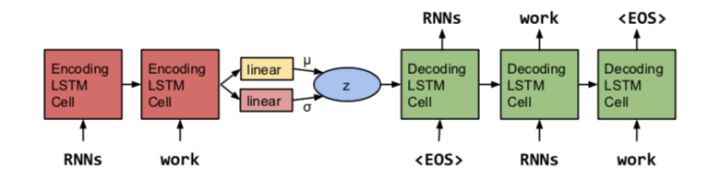
模型由三部分组成,Encoder,Decoder和VAE。
Encoder - rnn模型,论文中使用LSTM,通过rnn模型提取样本的序列特征。
Decoder - rnn模型,可以看做一个标准的Recurrent neural network language models(rnnlms)
VAE:能力不够,无法将论文中的意思很好的翻译成中文传达给大家,所以只能附上原文并带上自己的一点浅见:由于高位空间中空间过于庞大,仅仅使用latent variable生成样本会有明显失真,不管图片还是自然语言,所以在latent variable基础上强制使其服从某种有规律的几何概率分布,从而指导decoder生成逼真的样本。
论文描述

论文中使用 highway network layers 提高模型性能
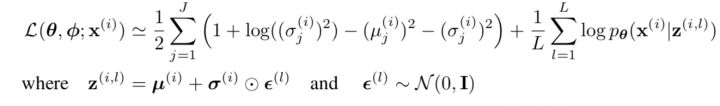
损失函数由两部分组成:
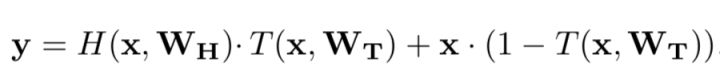
encoder由一层双向lstm构成,输出时间序列的总体特征。
class Encoder(nn.Module):
def __init__(self, embed_dim, hidden_size, num_layers, dropout):
super().__init__()
self.num_layers = num_layers
self.hidden_size = hidden_size
self.dropout = dropout
self.rnn = nn.LSTM(embed_dim, hidden_size,
num_layers, dropout, bidirectional=True)
def forward(self, input, hidden):
_, hidden = self.rnn(input.transpose(0, 1), hidden)
out = F.dropout(torch.cat((hidden[0][-2],
hidden[0][-1]), -1), p=self.dropout)
return out, hidden
def init_hidden(self, bsz):
size = (self.num_layers*2, bsz, self.hidden_size)
weight = next(self.parameters()).data
return (Variable(weight.new(*size).zero_()),
Variable(weight.new(*size).zero_()))
decoder为标准rnnlms
class Decoder(nn.Module):
def __init__(self, embed_dim, latent_dim, hidden_size, num_layers, dropout, vocab_size):
super().__init__()
self.hidden_size = hidden_size
self.dropout = dropout
self.num_layers = num_layers
self.latent_dim = latent_dim
self.rnn = nn.LSTM(embed_dim+latent_dim, hidden_size,
num_layers, dropout=dropout, batch_first=True)
self.lr = nn.Linear(hidden_size, vocab_size)
self._init_weight()
def forward(self, input, z, hidden):
bsz, _len, _ = input.size()
z = z.unsqueeze(1).expand(bsz, _len, self.latent_dim)
input = torch.cat((input, z), -1)
rnn_out, hidden = self.rnn(input, hidden)
rnn_out = F.dropout(rnn_out, p=self.dropout)
out = self.lr(rnn_out.contiguous().view(-1, self.hidden_size))
return F.log_softmax(out), hidden
def init_hidden(self, bsz):
size = (self.num_layers, bsz, self.hidden_size)
weight = next(self.parameters()).data
return (Variable(weight.new(*size).zero_()),
Variable(weight.new(*size).zero_()))
def _init_weight(self, scope=.1):
self.lr.weight.data.uniform_(-scope, scope)
self.lr.bias.data.fill_(0)
vae由embedding,highway,encoder, W_mu,W_alpha ,decoder组成
class VAE(nn.Module):
def __init__(self, args):
super().__init__()
for k, v in args.__dict__.items():
self.__setattr__(k, v)
self.lookup_table = nn.Embedding(self.vocab_size, self.embed_dim)
self.lookup_table.weight.data.copy_(torch.from_numpy(self.pre_w2v))
self.hw = Highway(self.hw_layers, self.hw_hsz, F.relu)
self.encode = Encoder(self.embed_dim,
self.enc_hsz, self.enc_layers, self.dropout)
self._enc_mu = nn.Linear(self.enc_hsz*2, self.latent_dim)
self._enc_log_sigma = nn.Linear(self.enc_hsz*2, self.latent_dim)
self.decode = Decoder(self.embed_dim, self.latent_dim,
self.dec_hsz, self.dec_layers, self.dropout, self.vocab_size)
self._init_weight()
def forward(self, enc_input, dec_input, enc_hidden, dec_hidden):
enc_ = self.lookup_table(enc_input)
enc_ = F.dropout(self.hw(enc_), p=self.dropout)
enc_output, enc_hidden = self.encode(enc_, enc_hidden)
z = self._gaussian(enc_output)
dec_ = self.lookup_table(dec_input)
dec, dec_hidden = self.decode(dec_, z, dec_hidden)
return dec, self.latent_loss, enc_hidden, dec_hidden
def _gaussian(self, enc_output):
def latent_loss(mu, sigma):
pow_mu = mu * mu
pow_sigma = sigma * sigma
return 0.5 * torch.mean(pow_mu + pow_sigma - torch.log(pow_sigma) - 1)
mu = self._enc_mu(enc_output)
sigma = torch.exp(.5 * self._enc_log_sigma(enc_output))
self.latent_loss = latent_loss(mu, sigma)
weight = next(self.parameters()).data
std_z = Variable(weight.new(*sigma.size()), requires_grad=False)
std_z.data.copy_(torch.from_numpy(
np.random.normal(size=sigma.size())))
return mu + sigma * std_z
def _init_weight(self):
init.xavier_normal(self._enc_mu.weight)
init.xavier_normal(self._enc_log_sigma.weight)
def generate(self, max_len):
size = (1, self.latent_dim)
weight = next(self.parameters()).data
z = Variable(weight.new(*size), volatile=True)
z.data.copy_(torch.from_numpy(
np.random.normal(size=size)))
prob = torch.LongTensor([BOS])
input = Variable(prob.unsqueeze(1), volatile=True)
if weight.is_cuda:
input = input.cuda()
portry = ""
hidden = self.decode.init_hidden(1)
for index in range(1, max_len+1):
encode = self.lookup_table(input)
output, hidden = self.decode(encode, z, hidden)
prob = output.squeeze().data
next_word = torch.max(prob, -1)[1].tolist()[0]
input.data.fill_(next_word)
if index%5 == 0:
portry += self.idx2word[next_word]
portry += ","
else:
portry += self.idx2word[next_word]
return portry[:-1] + "。"